LLM Reasoning Remains Deeply Flawed: A Critical Analysis
A deep dive into why large language models still struggle with reasoning, despite massive investments and ongoing hype.
The promise of artificial intelligence has always been tantalizing: machines that not only process information but reason, infer, and understand the world as humans do. Despite unprecedented advances in large language models (LLMs), recent research continues to reveal a persistent and fundamental gap: reasoning remains a core weakness. This article explores why LLMs struggle with reasoning, the implications for the future of AI, and what the latest research tells us about the road ahead.
Table of Contents
- The Persistent Challenge of Reasoning in LLMs
- A Decade of Critique: Why Reasoning Matters
- Industry Response: Scale vs. Substance
- New Evidence: Systematic Reasoning Failures
- Taxonomy of Reasoning Flaws
- What This Means for AGI Prospects
- FAQ
- Conclusion
The Persistent Challenge of Reasoning in LLMs
Since the rise of deep learning, reasoning has consistently been identified as a stumbling block for AI. While LLMs like GPT-4 and its successors can generate impressively human-like text and perform a wide array of tasks, their ability to reason—whether in formal logic, causal inference, or abstract thought—remains limited. This issue is not new. Thought leaders and researchers have pointed out these limitations for years, yet recent high-profile reviews show the problem is far from solved.
A Decade of Critique: Why Reasoning Matters
The Early Warnings
Over a decade ago, AI experts such as Gary Marcus and others highlighted that deep learning systems lack the mechanisms to represent causal relationships, handle abstract concepts, or perform logical inference. In a 2012 New Yorker article, Marcus presciently noted that deep learning was only a piece of the puzzle: “Such techniques lack ways of representing causal relationships (such as between diseases and their symptoms), and are likely to face challenges in acquiring abstract ideas.”
These early warnings were echoed by a chorus of respected academics, including Subbarao Kambhampati, Judea Pearl, Ernest Davis, Ken Forbus, Melanie Mitchell, Yann LeCun, Francesca Rossi, and even Ilya Sutskever. Yet, the dominant narrative in Silicon Valley often dismissed these critiques, focusing instead on rapid scaling and ever-larger models.

Industry Response: Scale vs. Substance
The “Scale Will Solve It” Fallacy
The prevailing industry response to concerns over LLM reasoning has been a relentless focus on scale. Billions—nearly a trillion dollars—have been poured into training larger and more complex models, under the assumption that more data and parameters would eventually yield reasoning abilities rivaling human intelligence. CEOs and tech leaders repeatedly promise that artificial general intelligence (AGI) is just around the corner—“next year, for sure.”
However, as year after year passes without the arrival of true AGI, it has become clear that simply scaling up does not address the core reasoning deficits in LLMs. Models still hallucinate, fabricate facts, and make inexplicable errors in tasks that require logical or causal inference.
New Evidence: Systematic Reasoning Failures
A comprehensive new review from Caltech and Stanford, titled “Large Language Model Reasoning Failure,” provides the most thorough taxonomy to date of where and how LLMs go wrong. The study reveals that, even among the latest systems specifically marketed for “reasoning,” major problems persist across a wide range of benchmarks and scenarios.
Key Findings
- Widespread Errors: Reasoning failures are not isolated incidents but occur across diverse tasks and datasets.
- Failure to Generalize: LLMs struggle to apply learned reasoning patterns to novel situations.
- Superficial Correlation: Many successes are driven by pattern matching rather than genuine understanding or inference.
For anyone seeking to grasp the reality of current AI capabilities and limitations, this review is essential reading. It also helps clarify why LLMs, despite their impressive fluency, are not yet the right answer for tasks demanding robust reasoning.
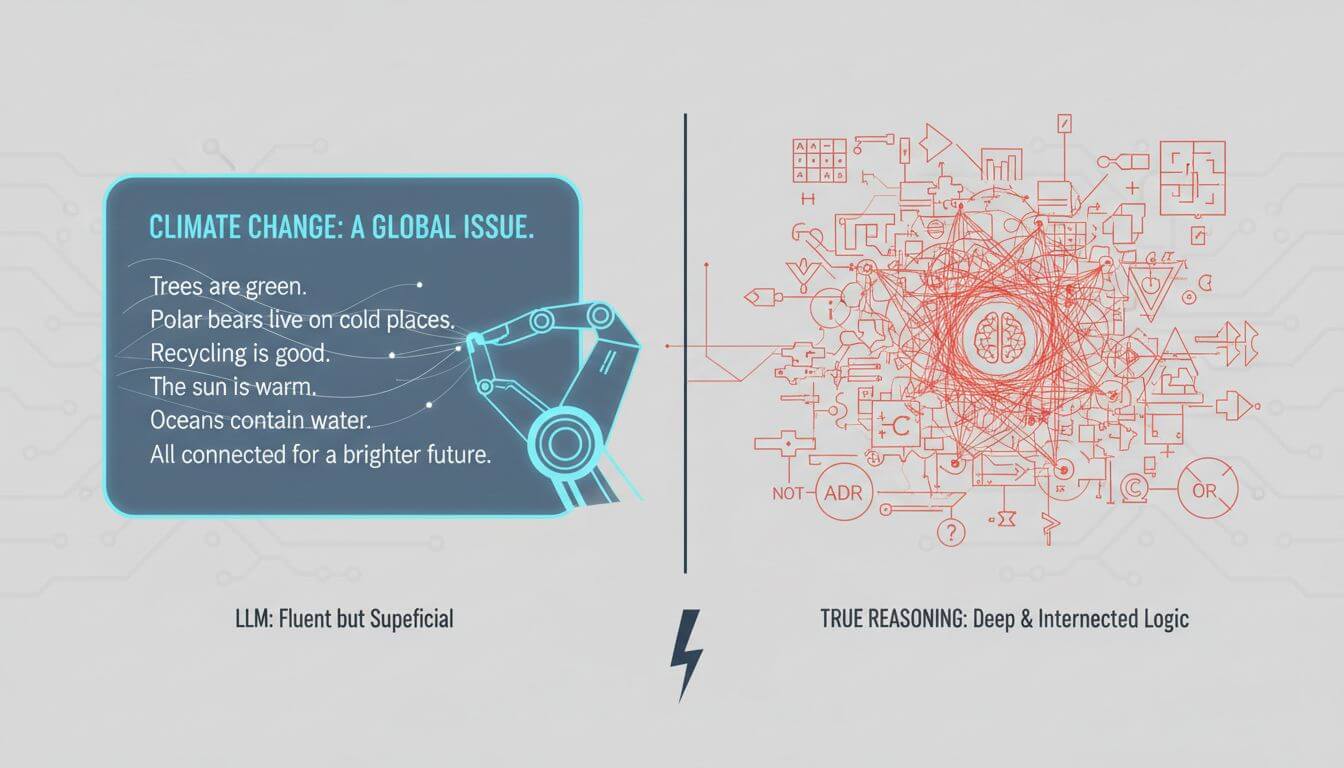
Taxonomy of Reasoning Flaws
The Caltech-Stanford review provides a detailed classification of reasoning failures in LLMs, including:
- Causal Reasoning Gaps: Difficulty in understanding cause-effect relationships.
- Logical Inference Errors: Struggles with consistent application of formal logic.
- Abstract Concept Handling: Challenges in generalizing to unseen or hypothetical scenarios.
- Hallucination and Fabrication: Generating plausible-sounding but incorrect or incoherent outputs.
These flaws highlight the fundamental difference between statistical pattern recognition and true reasoning. While LLMs excel at the former, they remain unreliable at the latter.
What This Means for AGI Prospects
The repeated failures of LLMs to achieve robust reasoning cast serious doubt on claims that AGI is imminent via current approaches. The review suggests that it may be time for the AI community to reconsider its heavy reliance on LLMs and invest in alternative paradigms that explicitly address reasoning, abstraction, and causal understanding.
Silicon Valley’s Fork in the Road
The industry now faces a choice: continue to dismiss legitimate criticism and hope for a breakthrough, or proactively address the limitations of LLMs by exploring new foundations for machine intelligence. True progress toward AGI may depend on embracing the latter path.
FAQ
Q: Why do LLMs still struggle with reasoning, even after massive investments? A: LLMs are fundamentally statistical pattern matchers; while they excel at mimicking text and surface-level tasks, they lack explicit mechanisms for logic, causality, and abstraction, which are central to true reasoning.
Q: Are there any LLMs that have solved reasoning? A: As of the latest research, even the most advanced and specialized LLMs continue to exhibit major reasoning flaws across a wide range of tasks.
Q: Does this mean LLMs are useless? A: Not at all—LLMs are valuable for text generation, summarization, and other tasks, but their outputs should not be mistaken for genuine understanding or reliable reasoning.
Conclusion
Despite years of progress and staggering investments, large language models remain fundamentally limited in their reasoning capabilities. The newest research underscores that scaling alone is not a solution, and the AI community must grapple with these challenges directly to make meaningful progress toward artificial general intelligence. For those working with AI-generated text, it’s also important to consider issues like hidden watermarks and metadata. If you need to clean AI-generated text, you might find Clean Paste helpful.
Related Reading:
